Entering edit mode

I am noticing an interesting trend on the dispersion plot where dispersion estimates are increasing for genes with extremely high counts:
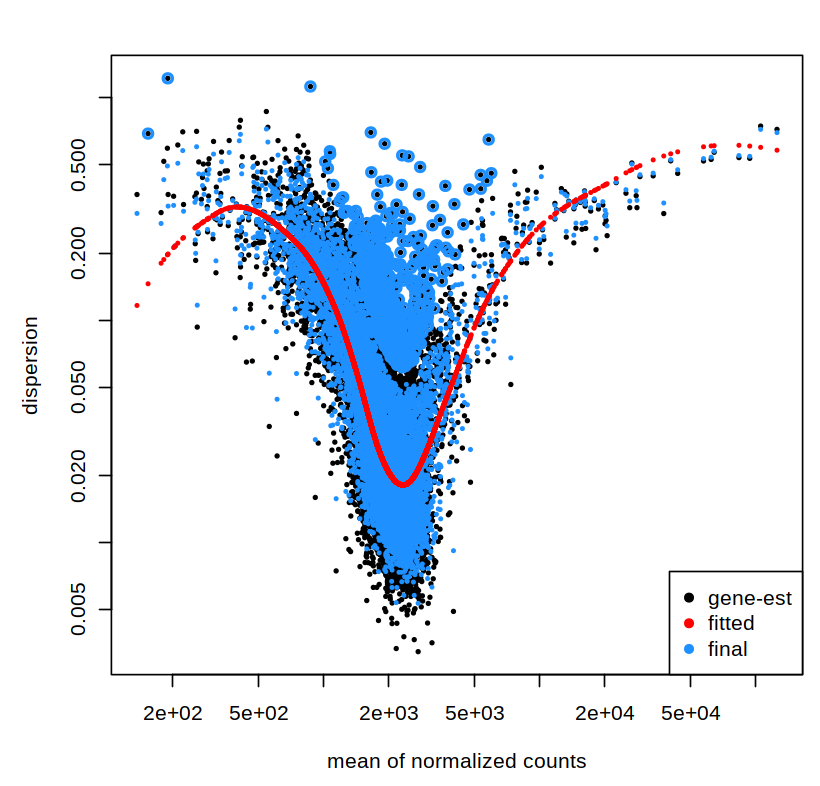
These are selection experiments where we expect a high degree of variance for highly-expressed genes (a given gene may be highly expressed in one condition but not another). Still, I think the model fit is generally performing fairly well across the range of counts in this example. Would you be wary of these dispersion estimates leading to unpredictable p-value estimates from the NB GLM?

Thanks very much for sharing your thoughts